miércoles, 4 de noviembre de 2015
lunes, 2 de noviembre de 2015
viernes, 30 de octubre de 2015
DESARROLLO DEL TEMA
Tema en sí:
ESTIMACIÓN ESTADÍSTICA

La dimensión estadística se divide en tres grandes bloques, cada uno de los cuales tiene distintos métodos que se usan en función de las características y propósitos del estudio:
I. ESTIMACION PUNTUAL
Una estimación es puntual cuando se usa un solo valor extraído de la muestra para estimar el parámetro desconocido de la población. Al valor usado se le llama estimador.
- La media de la población se puede estimar puntualmente mediante la media de la muestra:
- La proporción de la población se puede estimar puntualmente mediante la proporción de la muestra:
- La desviación típica de la población se puede estimar puntualmente mediante la desviación típica de la muestra, aunque hay mejores estimadores:



Por ejemplo, supongamos que la compañía Sonytron desea estimar la edad media de los compradores de equipos de alta fidelidad. Seleccionan una muestra de 100 compradores y calculan la media de esta muestra, este valor será un estimador puntual de la media de la población.
Otro ejemplo, si se pretende estimar la talla media de un determinado grupo de individuos, puede extraerse una muestra y ofrecer como estimación puntual la talla media de los individuos.
ESTIMADOR
Un estimador es una regla que establece cómo calcular una estimación basada en las mediciones contenidas en una muestra estadística.


A) INSESGADO.-
Un estimador es insesgado si su distribución tiene como valor esperado al parámetro que se desea estimar.
B) CONSISTENCIA.-
Un requerimiento lógico para un estimador es que su precisión mejore
al aumentar el tamaño muestral. Es decir, que esperaremos obtener mejores
estimaciones cuanto mayor sea el número de individuos.
Si se cumple dicho requerimiento, diremos que un estimador es consistente.
Desde un punto de vista más riguroso diremos que un estimador es consistente si
converge en probabilidad al verdadero valor del parámetro que queremos estimar.
- Ejemplo:
Consideremos el caso de la estimación de la media de una población Normal (μ) y consideraremos dos estimadores:
- Estimador 1: La primera observación de la muestra (para cualquier tamaño muestral).
- Estimador 2: La media aritmética de las observaciones.
Para observar el comportamiento de ambos estimadores utilizaremos el siguiente programa que genera automáticamente diez muestras de diferentes tamaños (n = 2; 10 ; 50; 500) procedentes de una distribución Normal de parámetros (μ = 0; σ = 1). Se tratará, por tanto, de un estudio de simulación (generamos muestras procedentes de una determinada distribución) para comparar el comportamiento de ambos estimadores. Recuerda que el verdadero valor del parámetro a estimar (μ) es cero y que corresponde a la línea central en negro:
Es evidente que el estimador correspondiente a la primera observación no mejora al aumentar el tamaño de la muestra. Mientras que la media aritmética converge hacia el verdadero valor del parámetro (μ = 0) al aumentar el tamaño de la muestra.
En resumen: la primera observación no es un estimador consistente de μ, mientras que la media aritmética sí que lo es.
C) EFICIENCIA.-
Hemos visto que parece razonable trabajar con estimadores centrados, sin embargo, ésta no puede ser la única propiedad que le pidamos a un estimador ya que, en general, podremos encontrar un gran número de estimadores centrados de un mismo parámetro. Por tanto, necesitaremos algún criterio adicional para seleccionar entre estimadores centrados y dicho criterio será la eficiencia.
Antes de entrar en definiciones volvamos a la metáfora del tiro a una diana y comparemos los resultados de dos tiradores:


Está claro que el centro de masas de los disparos de ambos tiradores está en el centro de la diana (son centrados o insesgados), pero si nos preguntan qué tirador preferiríamos de los dos claramente responderíamos que el Tirador 2.
Si analizamos ambos tiradores vemos que la dispersión alrededor del centro de la diana del Tirador 2 es muy inferior a la del Tirador 1. Por tanto, si sólo se dispone de un disparo, es más probable que sea el Tirador 2 el que haga blanco.
Traduciendo la discusión anterior a términos estadísticos, sabemos que la dispersión de una variable aleatoria la medimos habitualmente a través de su varianza. Por tanto, dados dos estimadores centrados de un mismo parámetro será razonable preferir el de menor varianza y diremos que éste estimador es más eficiente:

De manera gráfica: si T1, T2 y T3 son tres estimadores centrados de un mismo parámetro θ (observad que la esperanza de los tres es θ) y las gráficas de las funciones de densidad correspondientes son las siguientes:

Podemos preguntarnos ¿cuál es el estimador más eficiente de los tres?
El de menor varianza (menor dispersión respecto su esperanza) es T1, seguido de T2 y de T3:
V(T1) < V(T2) < V(T3)
Por tanto, T1 es el estimador más eficiente de los tres.

D) ERROR CUADRATICO MEDIO (ECM).-
Otro criterio razonable para escoger un determinado estimador de un parámetro θ es tomar aquel que cometa,
en promedio, el menor error en la estimación. Como, en principio, queremos penalizar igualmente los errores por defecto que por exceso podríamos establecer como cantidad a minimizar la esperanza de la diferencia entre el estadístico T y el parámetro θ (en valor absoluto para impedir que los errores por defecto y por exceso se anulen mutuamente):

Aunque este operador resulta razonable, presenta el inconveniente de que la función valor absoluto es complicada de manejar desde un punto de vista matemático. Por dicha razón suele utilizarse el error cuadrático medio (ECM) de un estimador T, definido como sigue:

Una propiedad interesante del ECM es que puede descomponerse como la suma de dos componentes: la varianza del estimador más su sesgo al cuadrado:

Por tanto, en el caso de comparar diversos estimadores centrados de un parámetro θ, el ECM coincidirá con sus varianzas. Con lo que el estimador con menor ECM coincidirá con el de menor varianza.
Debe quedar claro, sin embargo, que el estimador con menor ECM no debe ser necesariamente centrado. De hecho, no siempre existirá el estimador con ECM mínimo. En realidad, si no nos restringimos a estimadores centrados, suele suceder que para unos eterminados valores de θ sea un estimador el que produzca un ECM menor, mientras que para otros valores de θ sea otro estimador el que obtenga un ECM menor.
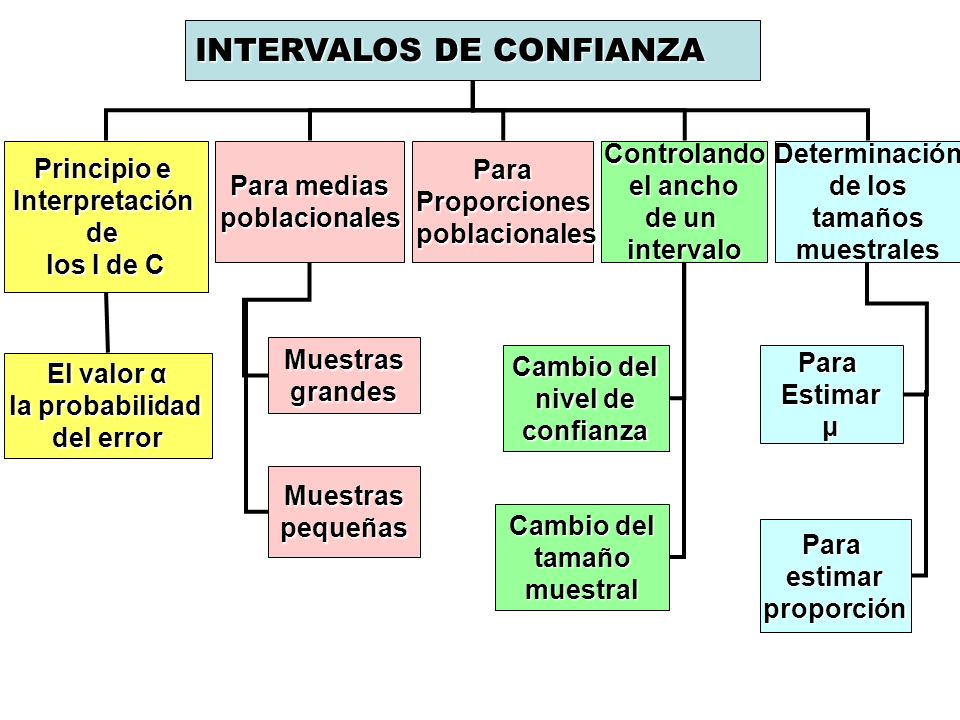
II. ESTIMACION POR INTERVALOS
A veces es conveniente obtener unos límites entre los cuales se encuentre el parámetro con un cierto nivel de confianza, en este caso hablamos de estimación por intervalos. Consiste en la obtención de un intervalo dentro del cual estará el valor del parámetro estimado con una cierta probabilidad. En la estimación por intervalos se usan los siguientes conceptos:
Intervalo de confianza
El intervalo de confianza es una expresión del tipo [θ1, θ2] ó θ1 ≤ θ ≤ θ2, donde θ es el parámetro a estimar. Este intervalo contiene al parámetro estimado con un determinado nivel de confianza. Pero a veces puede cambiar este intervalo cuando la muestra no garantiza un axioma o un equivalente circunstancial.

Variabilidad del Parámetro
Si no se conoce, puede obtenerse una aproximación en los datos aportados por la literatura científica o en un estudio piloto. También hay métodos para calcular el tamaño de la muestra que prescinden de este aspecto. Habitualmente se usa como medida de esta variabilidad la desviación típica poblacional y se denota σ.
Error de la estimación
Es una medida de su precisión que se corresponde con la amplitud del intervalo de confianza. Cuanta más precisión se desee en la estimación de un parámetro, más estrecho deberá ser el intervalo de confianza y, si se quiere mantener o disminuir el error, más observaciones deberán incluirse en la muestra estudiada. En caso de no incluir nuevas observaciones para la muestra, más error se comete al aumentar la precisión. Se suele llamar E, según la fórmula E = (θ2 - θ1)/2.
Límite de Confianza
Es la probabilidad de que el verdadero valor del parámetro estimado en la población se sitúe en el intervalo de confianza obtenido.
El nivel de confianza se denota por (1-α), aunque habitualmente suele expresarse con un porcentaje ((1-α)·100%). Es habitual tomar como nivel de confianza un 95% o un 99%, que se corresponden con valores α de 0,05 y 0,01 respectivamente.
Valor α
También llamado nivel de significación. Es la probabilidad (en tanto por uno) de fallar en nuestra estimación, esto es, la diferencia entre la certeza (1) y el nivel de confianza (1-α). Por ejemplo, en una estimación con un nivel de confianza del 95%, el valor α es (100-95)/100 = 0,05.
Valor crítico
Se representa por Zα/2. Es el valor de la abscisa en una determinada distribución que deja a su derecha un área igual a α/2, siendo 1-α el nivel de confianza. Normalmente los valores críticos están tabulados o pueden calcularse en función de la distribución de la población. Por ejemplo, para una distribución normal, de media 0 y desviación típica 1, el valor crítico para α = 0,1 se calcularía del siguiente modo: se busca en la tabla de la distribución ese valor (o el más aproximado), bajo la columna "Área"; se observa que se corresponde con -1,28. Entonces Zα/2 = 1,64. Si la media o desviación típica de la distribución normal no coinciden con las de la tabla, se puede realizar el cambio de variable t =(X-μ)/σ para su cálculo.
Con estas definiciones, si tras la extracción de una muestra se dice que "3 es una estimación de la media con un margen de error de 0,6 y un nivel de confianza del 99%", podemos interpretar que el verdadero valor de la media se encuentra entre 2,7 y 3,3, con una probabilidad del 99%. Los valores 2,7 y 3,3 se obtienen restando y sumando, respectivamente, la mitad del error, para obtener el intervalo de confianza según las definiciones dadas.
Para un tamaño fijo de la muestra, los conceptos de error y nivel de confianza van relacionados. Si admitimos un error mayor, esto es, aumentamos el tamaño del intervalo de confianza, tenemos también una mayor probabilidad de éxito en nuestra estimación, es decir, un mayor nivel de confianza.
III. ESTIMACION BAYESIANA
El enfoque bayesiano se basa en la interpretación subjetiva de la probabilidad, el cual considera a ésta como un grado de creencia con respecto a la incertidumbre.
Un parámetro es visto como una variable aleatoria a la que, antes de la evidencia muestral, se le asigna una distribución a priori de probabilidad, con base en un cierto grado de creencia con respecto al comportamiento aleatorio. Cuando se obtiene la evidencia muestral, la distribución a priori es modificada y entonces surge una distribución a posteriori de probabilidad.
Ejemplos de inferencia
Un ejemplo de inferencia bayesiana es el siguiente:
- Durante miles de millones de años, el sol ha salido después de haberse puesto. El sol se ha puesto esta noche. Hay una probabilidad muy alta de (o 'Yo creo firmemente' o 'es verdad') que el sol va a volver a salir mañana. Existe una probabilidad muy baja de (o 'yo no creo de ningún modo' o 'es falso') que el sol no salga mañana.
La inferencia bayesiana usa un estimador numérico del grado de creencia en una hipótesis aún antes de observar la evidencia y calcula un estimador numérico del grado de creencia en la hipótesis después de haber observado la evidencia. La inferencia bayesiana generalmente se basa en grados de creencia, o probabilidades subjetivas, en el proceso de inducción y no necesariamente declara proveer un método objetivo de inducción.









INTRODUCCIÓN
ESTIMACIÓN ESTADÍSTICA

VARIABLES
ESTADÍSTICA
La estadística es una ciencia formal y una herramienta que estudia el uso y los análisis provenientes de una muestra representativa de datos, busca explicar las correlaciones y dependencias de un fenómeno físico o natural, de ocurrencia en forma aleatoria o condicional.
Sin embargo, la estadística es más que eso, es decir, es la herramienta fundamental que permite llevar a cabo el proceso relacionado de la estadística con la investigación científica.
Es transversal a una amplia variedad de disciplinas, desde la física hasta las ciencias sociales, desde las ciencias de la salud hasta el control de calidad.
Se usa para la toma de decisiones en áreas de negocios o instituciones gubernamentales.

La estadística se divide en dos grandes áreas:
Estadística Descriptiva: Se dedica a la descripción, visualización y resumen de datos originados a partir de los fenómenos de estudio. Los datos pueden ser resumidos numérica o gráficamente. Ejemplos básicos de parámetros estadísticos son: la media y la desviación estándar. Algunos ejemplos gráficos son: histograma, pirámide poblacional, gráfico circular, entre otros.

Estadística inferencial: Se dedica a la generación de los modelos, inferencias y predicciones asociadas a los fenómenos en cuestión teniendo en cuenta la aleatoriedad de las observaciones. Se usa para modelar patrones en los datos y extraer inferencias acerca de la población bajo estudio. Estas inferencias pueden tomar la forma de respuestas a preguntas sí/no (prueba de hipótesis), estimaciones de unas características numéricas (estimación), pronósticos de futuras observaciones, descripciones de asociación (correlación) o modelamiento de relaciones entre variables (análisis de regresión). Otras técnicas de modelamiento incluyen análisis de varianza, series de tiempo y minería de datos.

Ambas ramas (descriptiva e inferencial) comprenden la estadística aplicada. La estadística inferencial, por su parte, se divide en estadística paramétrica y estadística no paramétrica.
RELACIÓN ENTRE ESTADÍSTICA DESCRIPTIVA Y ESTADÍSTICA INFERENCIAL

II. ESTIMACIÓN
Cuando queremos realizar un estudio de una población cualquiera de la que desconocemos sus parámetros, por ejemplo su media poblacional o la probabilidad de éxito si la población sigue una distribución binomial, debemos tomar una muestra aleatoria de dicha población a través de la cual calcular una aproximación a dichos parámetros que desconocemos y queremos estimar. Bien, pues esa aproximación se llama estimación.
Además, junto a esa estimación, y dado que muy probablemente no coincida con el valor real del parámetro, acompañaremos el error aproximado que se comete al realizarla.

TIPOS DE ESTIMACIONES:
- Estimación estadística: conjunto de técnicas que permiten dar un valor aproximado de un parámetro de una población a partir de los datos proporcionados por una muestra.
- Estimación numérica: serie de técnicas de análisis numérico para aproximar el valor numérico de una expresión matemática.
- Signo de estimación: marca que por ley debe ser impresa en productos pre empaquetados en venta en la Unión Europea y que certifica que el contenido real del paquete cumple los criterios exigidos de estimación de masa o volumen nominal.
Facultad de Ciencias Sociales - Escuela Académico Profesional de Trabajo Social - Visión y misión
TRABAJO SOCIAL
FACULTAD DE CC.SS - E.A.P. TRABAJO SOCIAL

VISIÓN:
Ser una facultad que se construya progresivamente en el tiempo; generando espacios que garanticen la formación de nuevos profesionales para satisfacer las necesidades del mercado con una aproximación a la excelencia.
MISIÓN:
La nueva Facultad de Ciencias Sociales concibe su desarrollo académico en el ámbito general de tres grandes misiones: La Formativa, La de Investigación y De Apoyo a la Gestión; Aplicada conjuntamente en las tres escuelas profesionales: Sociología, Trabajo Social y Ciencias de la Comunicación: con el fin de contribuir con el desarrollo de nuestro país y el bienestar de la población.
Universidad Nacional Federico Villarreal - Visión y Misión
"UNIVERSIDAD NACIONAL FEDERICO VILLARREAL"

VISIÓN:
"La Universidad Nacional Federico Villarreal" será una comunidad académica acreditada bajo estándares globales de calidad, posicionada internacionalmente, y al servicio del desarrollo humano sostenible.
MISIÓN:
"La Universidad Nacional Federico Villarreal" tiene por misión, la formación de la persona humana, y el fortalecimiento de la identidad cultural de la nación, fundado con el conocimiento científico y tecnológico, en correspondencia con el desarrollo humano sostenible.

PRESENTACIÓN
PRESENTACIÓN

| Apellidos y nombres: | Gonzales Falero, Cecilia Paola. |
| Facultad: | Ciencias Sociales. |
| Escuela Académico Profesional: | EAP Trabajo Social. |
| Curso: | Estadística Social II |
| Profesor: | Demetrio Ccesa Rayme. |
| Tema: | Estimación Estadística. |
| Año: | 2° |
| Ciclo: | cuarto |